
88% of companies now use AI somewhere in their stack. Only 39% see measurable results. The gap is not intelligence. It is data architecture. And the fastest way to close it in 2026 is a protocol most data teams still have not configured: the Omni MCP server.
I have been using Omni's MCP integration with Claude and Cursor for months now, across multiple client engagements. What started as a curiosity has become the single most impactful change to how I interact with governed data. This is not a product review. This is a practitioner's breakdown of what the Omni MCP actually unlocks, how to set it up properly, and why it matters for your data infrastructure strategy.
What the Omni MCP Server Actually Does
MCP stands for Model Context Protocol. Anthropic open-sourced it in late 2024, and by early 2026 it had become the standard interface for connecting AI tools to external data sources. Think of it as USB for AI integrations. One protocol, many tools, zero custom code per connection.
Omni's MCP server sits on top of their semantic layer. That distinction matters. When you connect Claude or Cursor to Omni via MCP, you are not sending raw SQL to a database. You are routing natural language questions through a governed business model that enforces metric definitions, access controls, and business logic before any query reaches your warehouse.
The server exposes three core tools: pickModel (selects which data model to query), pickTopic (narrows to a specific curated dataset), and getData (executes the actual query). This dynamic flow means you can switch between models mid-session without reconfiguring anything.
Why the Semantic Layer Is the Missing Piece in AI Analytics
Most AI analytics implementations skip the semantic layer entirely. They connect an LLM directly to a database and hope the model figures out what "revenue" means. It does not. Or worse, it does, but differently every time.
This is the core problem with text-to-SQL. It looks incredible in demos. It fails spectacularly in production. Gartner estimates 60% of AI projects will be abandoned because the data underneath is not AI-ready. Not because the models are weak. Because the data foundation is missing.
Omni's approach solves this structurally. The semantic layer acts as the intelligence backbone. It teaches the AI your specific business language: your metrics, your definitions, your logic. When Claude generates a query through Omni's MCP, it is constrained by the same governance rules your data team already maintains. The AI cannot hallucinate a metric that does not exist in the model.
For every dollar companies spend on AI, they should be spending six on the data architecture underneath it. The Omni MCP is one of the rare tools that actually enforces this principle by design.
Setting Up the Omni MCP in Cursor: A Practitioner's Guide
The official docs walk you through the configuration. Here is what they do not tell you.
Cursor now supports MCP servers natively. You configure them in an mcp.json file under Settings > Tools & Integrations. For Omni, you have two authentication paths: OAuth (recommended for individual use) and API key (better for teams and automated workflows).
The OAuth path is the fastest. You paste a single URL into your mcp.json, click Connect, authorize through your browser, and Omni creates a Personal Access Token linked to your user account. The entire setup takes under two minutes.
For API key authentication, you need your Omni instance URL, an API key, and optionally a model ID and topic name to scope the connection. Here is where it gets interesting. If you leave the model ID blank, Cursor will dynamically select the right model based on your question. If you lock it to a specific model, you reduce latency but lose flexibility.
My recommendation: start with a scoped model ID for your primary dataset, then create a second MCP configuration without model scoping for exploratory work. Cursor handles multiple MCP servers well, especially since the January 2026 update that reduced token usage by 47% across connected servers.
Using the Omni MCP with Claude Desktop and Claude Code
The Claude integration is even more seamless since Omni launched their native Claude connector in March 2026. Two clicks and you are connected. Every query respects your Omni permissions, your semantic model, and your topic definitions.
What makes the Claude integration powerful is chaining. You connect Omni alongside Google Docs, Google Calendar, or Slack. Then you ask compound questions. "Pull last quarter's revenue by segment from Omni, then draft a board update in the format of this Google Doc." Claude orchestrates across tools. Omni handles the data governance. You get a board-ready document in thirty seconds.
Claude Code takes this further for data engineering workflows. You can query Omni for schema context, generate dbt models based on actual metric definitions, and validate transformations against live data. The semantic layer becomes your pair programming partner's reference manual.
What I Learned Running Omni MCP Across Client Engagements
Three patterns emerged from six months of production use.
Pattern one: the semantic layer compounds over time. Every time a data team improves a metric definition or adds AI-specific context to an Omni topic, every MCP consumer gets smarter. This is the network effect that text-to-SQL lacks entirely. A well-maintained semantic layer is not just a BI feature. It is data infrastructure that serves every AI touchpoint in your organization.
Pattern two: non-technical users adopt faster than expected. The breakthrough is not the MCP itself. It is that business users can now ask data questions in Claude, the same interface they use for everything else. No new tool to learn. No dashboard to navigate. They type a question and get a governed answer. Omni's MCP removes the last-mile friction between data teams and business stakeholders.
Pattern three: governance becomes a feature, not friction. Every MCP query inherits user-level permissions from Omni. Row-level security, metric scoping, topic restrictions. All enforced automatically. This is the difference between a data governance policy that lives in a wiki and one that executes in production. Data quality and access controls become invisible infrastructure rather than manual checkpoints.
The Competitive Landscape: Why This Matters Now
Omni is not the only analytics platform with an MCP server. Cube has published extensively about MCP and semantic layers. Looker has its own approach through LookML. But Omni is the only platform where the semantic layer, the AI query engine, and the MCP server were designed as a single integrated system.
The MCP ecosystem has exploded to over 5,000 servers. Anthropic donated the protocol to the Agentic AI Foundation under the Linux Foundation in December 2025, with support from Block and OpenAI. Google DeepMind brought Gemini support. This is not an experiment anymore. MCP is the standard way AI tools connect to external data.
For data teams evaluating their AI readiness strategy, the question is no longer whether to support MCP. It is whether your semantic layer is good enough to make MCP useful. A raw database connection through MCP is still just text-to-SQL with extra steps. A governed semantic model through MCP is a fundamentally different capability.
The Intelligence Allocation Lesson
In 2019, I wrote about how every company was hiring Data Engineers to clean up the mess from the dashboard era. In 2026, the same pattern is repeating. Companies are buying AI tools and discovering that without a proper data foundation, the tools produce confident-sounding nonsense.
The Omni MCP server is a concrete example of what happens when you build intelligence at the right layer. The semantic layer sits between your raw data and your AI applications. It translates business logic for machines. It enforces governance without manual intervention. It makes every AI consumer smarter by default.
91% of organizations say a data foundation is essential for AI. Only 55% think they actually have one. If you are in the 45% that knows the foundation is missing, start there. Fix the floor before you let the agents run.
If you already have a semantic layer in Omni, connect the MCP today. You will not go back to the old way of querying data. And if you do not have a semantic layer yet, that should be the priority. Not another AI agent. Not another chatbot. The layer that makes all of them trustworthy.

More from Unwind Data
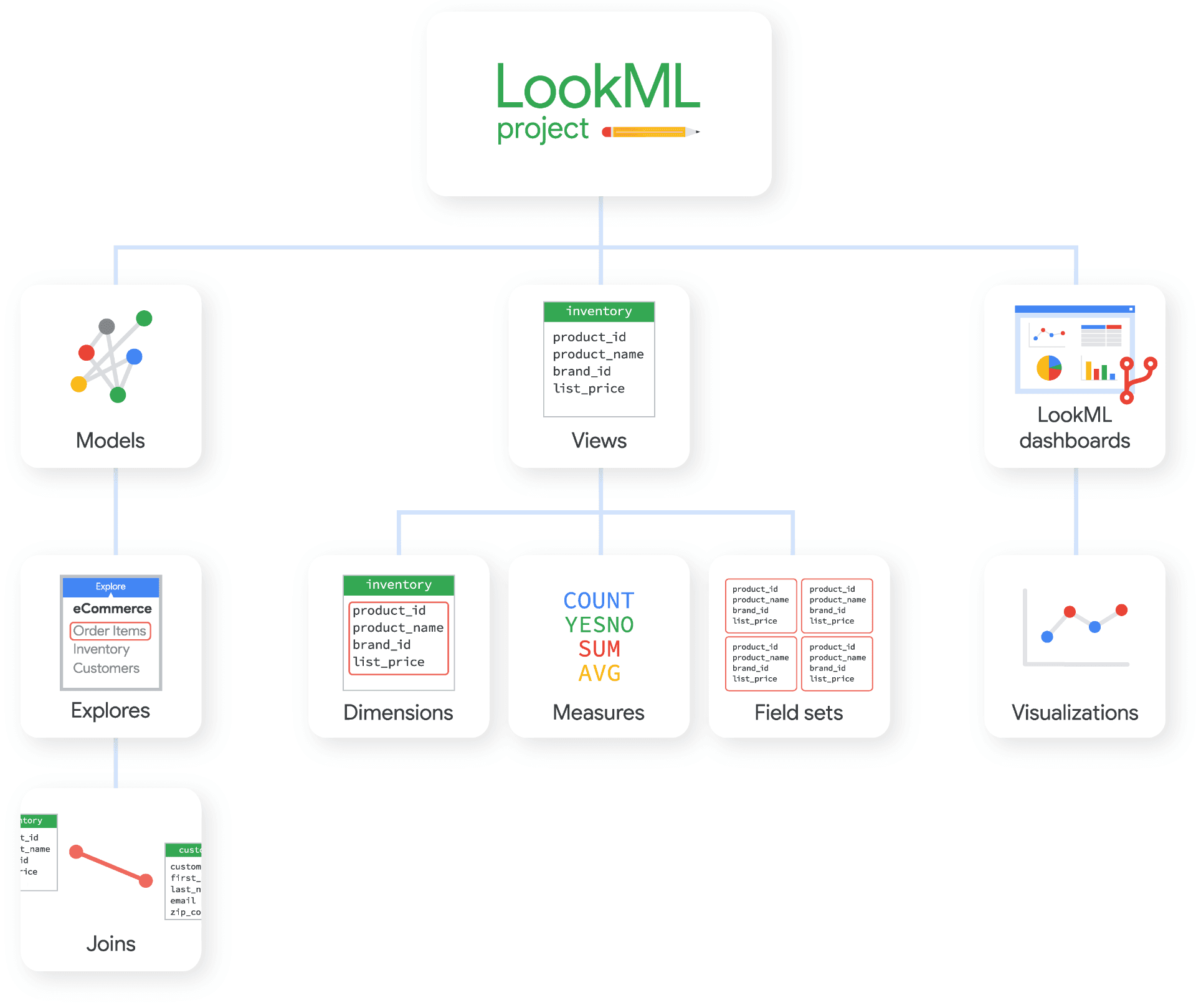
The Complete LookML Guide for 2026: Core Concepts and the dbt Migration Decision
A practitioner's guide to LookML in 2026: what views, dimensions, measures, and explores actually do, how LookML compares to the dbt Semantic Layer, and how to make the migration decision for enterprise teams.

Google Officially Separated Looker from Data Studio
Google just reversed the Looker Studio rebrand, reinstating Data Studio for the free tool and keeping Looker exclusively for enterprise governed analytics. For those of us who spent years explaining LookML to confused clients, this is overdue.

The Complete Guide to Every OSI Open Semantic Interchange Participant
A comprehensive guide to every organization in the Open Semantic Interchange initiative. What they do, where they fit, and what it means for your data strategy.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch