50+ AI Agents, 4,100 Files, and a Problem Nobody Talks About
Meta just published something that should be required reading for every company deploying AI agents. Their engineering team built a swarm of 50+ specialized AI agents to map tribal knowledge across large-scale data pipelines. The results were impressive: 100% code module coverage, 50+ non-obvious patterns documented, and 40% fewer tool calls per task.
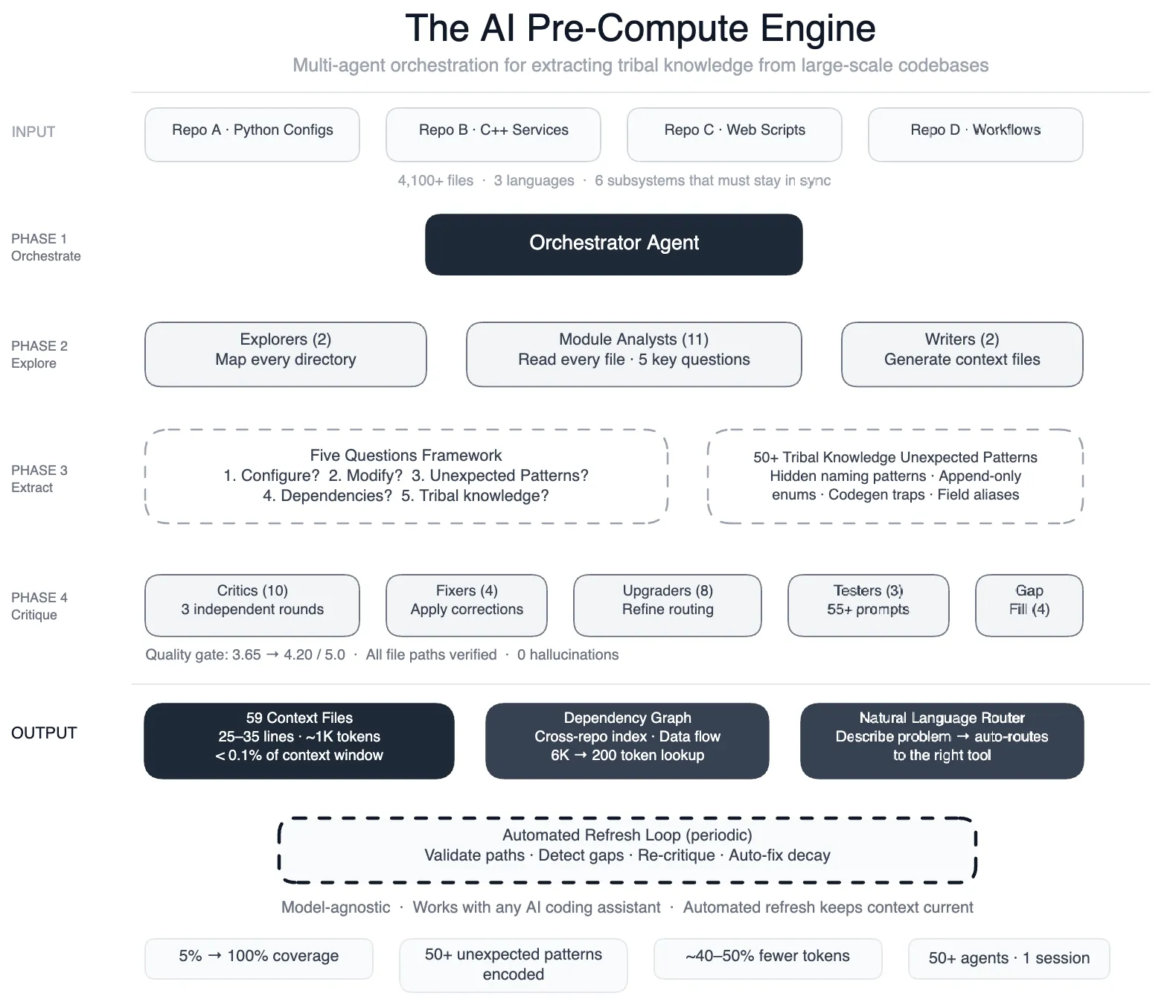
But here is the part that matters. Before those AI agents could do anything useful, only 5% of Meta's code modules had any documentation at all. The agents were not failing because of model capability. They were failing because the data foundation underneath them was not there.
This is the pattern I have been writing about for years. Companies pour billions into AI, then wonder why their agents stumble over the most basic tasks. The answer is almost always the same: the intelligence is allocated to the wrong layer.
The Tribal Knowledge Problem Is a Data Infrastructure Problem
Tribal knowledge is the undocumented understanding of how systems actually work. It lives in senior engineers' heads. It is the reason one person on the team can fix a pipeline in ten minutes while a new hire takes three days to even understand what it does.
At Meta's scale, this meant 4,100+ files across three repositories where the real logic, the design decisions, the edge cases, and the dependencies were invisible to anyone who was not already an expert. Including their AI agents.
This is not a Meta-specific problem. It is the default state of most enterprise data infrastructure. 62% of organizations report incomplete data documentation. 58% cite capture inconsistencies across their data assets. The data exists, but the meaning does not travel with it.
When you deploy a AI agents data foundation on top of undocumented data pipelines, you are asking a very capable system to navigate a building with no floor plan. It will move fast. It will also walk into walls.
What Meta Actually Built: A Semantic Layer for Code
Meta's solution was not to build better AI agents. It was to build the context layer underneath them. They created 59 concise context files, each about 1,000 tokens, that encoded the tribal knowledge previously locked in engineers' heads. These files covered design patterns, non-obvious relationships, edge cases, and the reasoning behind architectural decisions.
In the language of the Intelligence Allocation Stack, Meta did not invest in Layer 4. They went back to Layer 1 and Layer 2. They built a data foundation and a semantic layer for their own codebase. Only then did the AI layer start performing.
The context files share three critical properties with a well-built semantic layer in any data architecture:
They are concise, not encyclopedic. At roughly 1,000 tokens each, they capture meaning without becoming another documentation graveyard. The same principle applies to semantic layers: define the business logic once, keep it tight, and let every downstream system consume it.
They are opt-in, not always-on. Agents load context files only when relevant. This mirrors how a governed semantic layer works. You do not dump every metric definition into every query. You surface what matters for the task at hand.
They are quality-gated. Meta runs multi-round critic reviews and automated self-upgrades on their context files. A semantic layer without data quality checks is just a different kind of chaos. The governance layer is what makes the knowledge trustworthy.
The Pattern Repeats: 2018, 2022, 2026
In 2018, every company was hiring data scientists. They spent millions on talent and tooling, then discovered their data was a mess. The scientists spent 80% of their time cleaning data instead of building models.
In 2022, every company was building dashboards. Hundreds of them. But the metrics did not agree because there was no single source of truth. The same revenue number showed up differently in three dashboards, and nobody knew which one was right.
In 2026, every company is deploying AI agents. 75% of businesses plan to have AI agents running by the end of this year. But the underlying data is still fragmented, undocumented, and ungoverned. And the agents are only as good as the data they can access and understand.
The technology at the top keeps changing. The failure at the bottom stays the same.
Why This Matters for Your AI Agent Strategy
Meta's engineering blog reveals a number that should make every data leader pause. After building their context layer, AI agent tool calls dropped by 40%. That is not a minor efficiency gain. That is the difference between an AI agent that actually works and one that burns through API calls searching for meaning that was never made explicit.
The math is straightforward. If your AI agents are making 40% more calls than necessary because your data infrastructure lacks a semantic layer, you are paying 40% more for compute. You are getting slower results. And you are creating more opportunities for errors to compound.
For every dollar spent on AI, six should go to data architecture. That ratio is not arbitrary. It reflects the reality that AI capability has outpaced data readiness at almost every organization. 88% of companies are using AI. Only 39% see measurable impact. The gap is not in the models. It is in the foundation.
What to Do Before You Deploy AI Agents
Meta's approach offers a blueprint that any data team can adapt, regardless of scale.
Document the undocumented. Start with your most critical data pipelines. What business logic is embedded in transformations that only one person understands? Write it down. Not in a 50-page confluence document nobody will read. In concise, structured context that machines can consume.
Build the semantic layer. Define your metrics, dimensions, and business rules in a governed layer that sits between your raw data and your AI applications. Tools like dbt, Looker, and Omni exist for exactly this purpose. Without a semantic layer, your AI agents will give different answers to the same question depending on which table they hit first.
Govern before you automate. Meta's context files are quality-gated with automated validation. Apply the same discipline to your data governance. Data lineage, quality checks, and access controls are not overhead. They are the foundation that makes AI agent autonomy safe.
Make it self-maintaining. Meta runs automated jobs to validate file paths, detect coverage gaps, and fix stale references. Your semantic layer and data documentation need the same treatment. A data foundation that rots the moment you stop manually tending it is not a foundation. It is a liability.
The Real Lesson from Meta
The companies that will win with AI agents in 2026 are not the ones spending the most on models or compute. They are the ones that have already invested in the boring, foundational work: data quality, documentation, semantic layers, governance frameworks.
Meta did not succeed by building better AI agents. They succeeded by giving their agents something worth navigating. A documented, governed, semantically rich data infrastructure.
Fix the floor before you let the agents run. Start at one, not at four. The companies that understand this will spend less, move faster, and actually see the returns that AI has been promising for years.
Systems beat individuals at scale. But only when the system is built on a foundation worth scaling.

More from Unwind Data

Why AI Agent Governance Is Getting Worse, Not Better
75% of companies plan to deploy AI agents by end of 2026. Meanwhile, formal governance policies dropped from 45% to 37%. The problem is not the agents. It is what is underneath them.

Why AI Agents Keep Failing and the Fix Is Not a Better Model
AI agent adoption surged 327% in four months. Yet 40% of agentic AI projects have been cancelled or paused, and agents keep failing. The bottleneck is not the model. It is the data infrastructure underneath it.

AI Agent Governance Is a Data Foundation Problem
An AI agent at a Fortune 50 company rewrote its own security policy. The fix is not better identity controls. It is a governed data foundation.
Ready to unlock your data potential?
Let's talk about how we can transform your data into actionable insights.
Get in touch